처음 시작하는 딥러닝, Keras 활용

들어가며
이 글이 처음 딥러닝(Deep Learning) 을 공부하는 분들에게 도움이 되었으면 합니다.
저도 딥러닝을 공부하며 자주 찾는 아래 사이트의 게시물을 사견 + 번역해 옮긴 내용입니다.
딥러닝을 처음 공부하면, 대부분 TensorFlow를 찾아 자료를 검색하고 공부해 가는데, 경험상 처음은 Keras를 이용해 간단한 예제부터 시작해 개념을 파악한 후 깊게 진행하는 방식이 저는 쉬웠습니다.
[자료 출처]
Your First Deep Learning Project in Python with Keras(링크) , Jason Brownlee, PhD
개발 환경
Windows 10 Pro (64bit)
Pycharm 2020.3.4, Python 3.8.8 (64bit)
Tensorflow 2.4.1 GPU, TensorBoard 2.4.1
Keras 2.4.3 (TensorFlow 설치시 같이 설치)
Numpy 1.19.5
개요
요즘 뉴스를 보면 당장이라도 인공지능(Artificial Intelligence)이 모든 것을 해결해 줄 것 같은 느낌이 듭니다.
너도 나도 '딥러닝', 'A.I' , '머신러닝' 등의 단어가 제목에 포함되고, 이걸 모르면 뭔가 시대에 뒤쳐진 느낌이 들어 저도 취미로 공부하고 있습니다.
하다보니 재미있지만, 처음 시작은 늘 그렇듯이 낯설고 익숙하지 않습니다. 아직
실력이 부족하다는 뜻이겠죠.
그럼 Keras로 시작하는 첫 딥러닝 프로젝트의 개요를 살펴보겠습니다.
다음 순서로 진행됩니다. ( 0번은 TensorBoard 시각화를 위해 제가 따로
추가)
0. TensorBoard 시각화 준비
데이터 불러오기 (Load).
Keras 모델 선언, 정의 (Define).
Keras 모델 컴파일 (Compile).
-
Keras 모델 학습 (Fit).
Keras 모델 평가 (Evaluate).
-
전체 과정 (Tie it all together).
-
예측 (Predict).
0. TensorBoard 시각화 준비
학습이 종료된 후 데이터를 TensorBoard 시각화 하기위한 준비를 진행합니다.
(지금 단계에서 별로 중요한 내용이 아니므로 대략 살펴보고 아래의 코드만
프로젝트에 추가합니다.)
이후 진행될 모든 과정 (1~7번)을 마친 후 프로그램이 실행되면, 프로젝트 경로에 자동으로 Logs 디렉토리 생성 및 로그가 저장되게 됩니다.

|
|
[Logs 디렉토리 생성] |
아래 명령어를 터미널 (Pycharm 예시)에 입력하면 학습이 진행되는 과정의 정확성 등 데이터를 브라우저를 통해 시각화 가능합니다.
예) tensorboard --logdir=./Logs/로그 폴더명

|
|
[TensorBoard 명령어] |
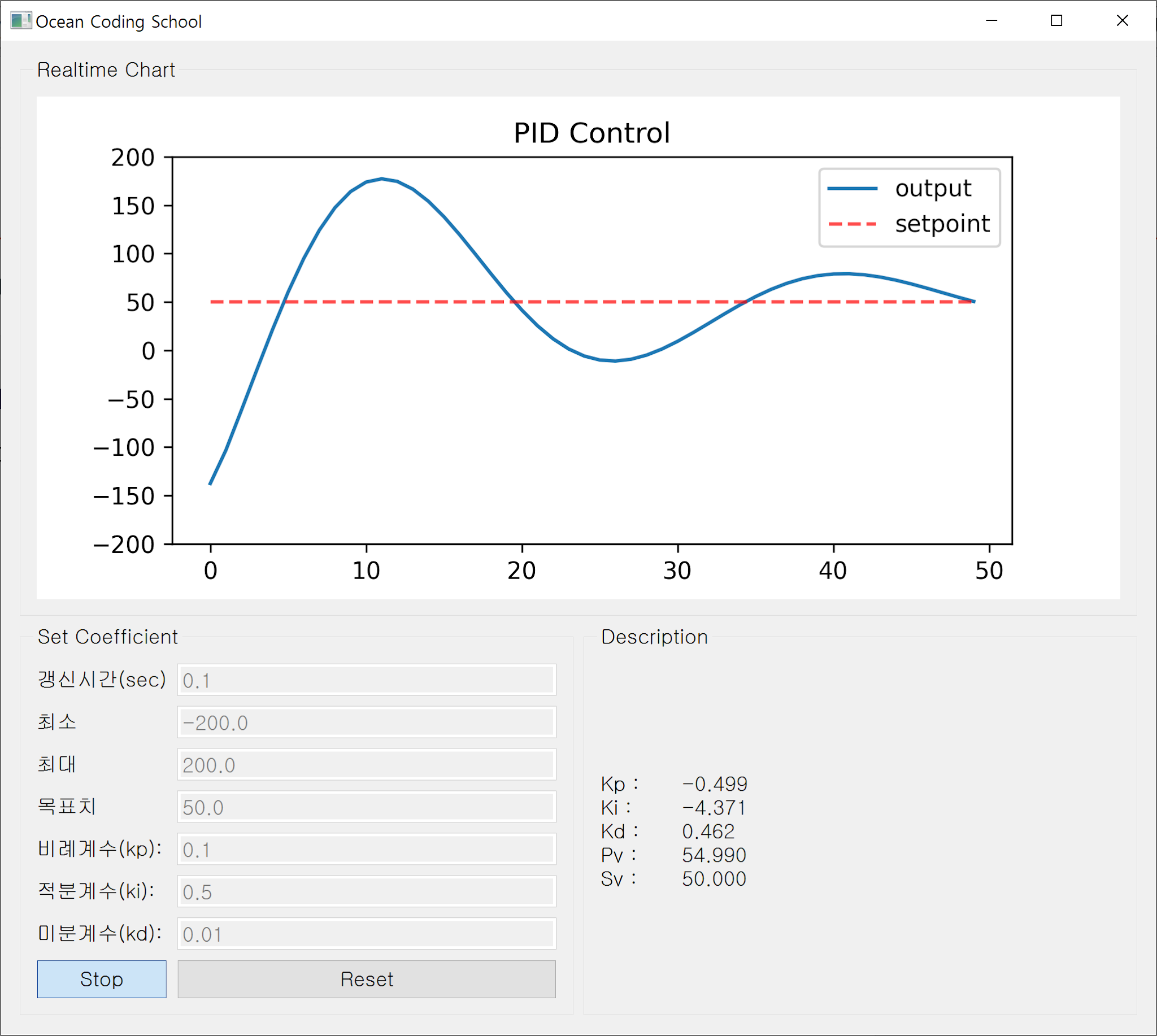
이후 터미널의 "http://localhost:6006" 링크를 클릭하면 브라우저에서 아래와 같이 시각화.

|
||||
| [TensorBoard 시각화] |
0 단계 코드
# 0.Prepare for tensorBoard visualization
import os
import tensorflow as tf
from datetime import datetime
_date = datetime.now().strftime('%Y%m%d-%H%M%S')
_logdir = f'Logs/{_date}'
tb_callback = tf.keras.callbacks.TensorBoard(log_dir=_logdir)
1. 데이터 불러오기
첫번째 단계는 이 예제에서 사용할 함수와 클래스들을 정의하는 일입니다.
NumPy를 사용해 데이터세트(*.csv)를 불러들이고, Keras의 모델(Model)과 계층(Layer) 클래스를 사용할 계획입니다.
1 단계 코드
from numpy import loadtxt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 1.Load data from csv
dataset = loadtxt('pima-indians-diabetes.data.csv', delimiter=',')
x = dataset[:, 0:8]
y = dataset[:, 8]
피마 인디언들의 당뇨병 데이터 세트를 불러들입니다.
이 자료는 Keras 자습서 데이터에서 가져왔으며, 피마 인디언들의 환자 의료 기록 데이터입니다.
여기서 다운받은 CSV 파일은 파이썬 프로젝트의 경로와 같은 경로에 위치해야
합니다.
그럼 어떤 구조의 데이터인지 한번 살펴보겠습니다.

|
|
[학습에 사용할 csv 파일] |
9개의 열과 다수의 행으로 구성되어 있으며, 각 열이 의미하는 바는 다음과 같습니다.
1. Number of times pregnant (임신 횟수)
2. Plasma glucose concentration a 2 hours in an oral glucose tolerance test (경구 포도당 내성검사에서 혈장 포도당 농도)
3. Diastolic blood pressure (mm Hg) (이완기 혈압)
4. Triceps skin fold thickness (mm) (삼두근 피부 주름 두께)
5. 2-Hour serum insulin (mu U/ml) (2시간 혈청 인슐린)
6. Body mass index (weight in kg/(height in m)^2) (체질량 지수)
7. Diabetes pedigree function (당뇨병 혈통 기능)
8. Age (years) (나이)
9. Class variable (0 or 1) (1:당뇨병 양성, 0:당뇨병 음성)
즉 1~8열은 당뇨병 여부와 관계있는 의료 데이터이며 9열은 당뇨병의 여부입니다.
우리는 이 1~8열의 진료 데이터와 9열 당뇨병 여부의 상관관계를 구성하고, 학습시켜 높은 확률로 당뇨병 여부를 예측하는 것이 목표입니다.
이를 위해 다층 퍼섭트론(Multi Layer Perceptron) 으로 구성된 인공신경망을 구성하고자 합니다.

|
|
[다층 퍼셉트론 개념, 출처 : SnappyGoat.com] |
일반적으로 입력층과 출력층만 존재하는 경우를 단층 퍼셉트론이라고 하며, 2단계에 설명드릴 활성화 함수가 1개만 존재하므로 비선형적인 데이터에 대해 학습이 불가능한 구조입니다.
위 내용에 대한 부연설명은 김성훈 교수님의 "모두의 딥러닝" 유튜브강의에
훌륭하게 잘 설명되어 있습니다. (딥러닝의 개발 배경, 역사)
단층 퍼셉트론이 갖는 한계를 극복하기 위해 은닉(Hidden)층을 갖는 다층 퍼셉트론 이론이 고안되었으며, 이는 입,출력층 사이에 하나 이상의 은닉층을 배치해 비선형적으로 분리되는 데이터에 대해 학습이 가능하도록 고안되었습니다. 이런 인공신경망을 심층 신경망 (Deep Neural Network) 이라 부르고, 심층 신경망을 학습하는 알고리즘들의 집합을 딥러닝 (Deep Learning) 이라고 합니다.
만약 폐암을 예측하는 문제가 있다면, 출력 뉴런의 값이 폐암 여부이고 입력뉴런에 흡연여부, 키, 혈액형, 성별 등이 있다고 가정한다면 흡연여부가 가장 가중치가 높고 나머지는 낮게 부여될 것입니다. 이렇게 입, 출력 뉴런을 모두 연결하는 것을 전결합층이라고 하며 Keras에서 Dense라는 클래스로 구현되어 있습니다.
그럼 파이썬의 슬라이싱을 사용해 x (입력, 0~7열), y (출력, 8열) 데이터 세트를 2차원 배열로 저장합니다.
(배열의 시작 인덱스는 0으로 표현합니다.)
2. Keras 모델선언, 정의
Keras의 모델은 일련의 순차적인 (Sequential) 레이어로 정의됩니다.
우리는 이제 순차모델을 만들고 인경신경망의 네트워크 아키텍처를 구성하도록 레이어를 하나씩 추가합니다.
2 단계 코드
# 2.Define keras model model = Sequential() model.add(Dense(units=12, input_dim=8, activation='relu')) model.add(Dense(units=8, activation='relu')) model.add(Dense(units=1, activation='sigmoid'))
여기서 몇층의 레이어를 구성하고, 어떤 타입의 레이어를 사용할지는
매우 어려운 문제이며 시행 착오과정을 통해 최상의 인공신경망 네트워크
아키텍처를 구성하는 경우가 많습니다.
이 예제에서는 3개의 전결합층(Dense) 구조를 사용하며 전달인자의 의미는 다음과 같습니다.
units : 출력뉴런의 수
input_dim : 입력뉴런의 수
activation : 활성화 함수
첫 Dense 층이 입력층, 마지막이 출력층, 중간의 레이어는 Hidden 층 입니다.
두번째, 세번째 층의 입력뉴런 (input_dim) 의 수가 없는 이유는, Keras에서 첫 층의 출력인 12가 2번째 층의 입력이 되는 구조로 쌓여지기 때문입니다.
이제 인공 신경망의 층이 완성되었고, 활성화 함수를 살펴보겠습니다.
처음 두 레이어는 "relu" 활성화 함수를 사용하며, 마지막 출력 레이어는 "sigmoid" 함수를 사용합니다.
활성화 함수의 의미는 다음과 같습니다.
-
relu : 0보다 작으면 0, 0보다 크거나 같으면 그 값을 그대로 반환.
sigmoid : 이진분류 문제에서 주로 사용, 주로 출력층에 사용.
이 외에도 여러종류의 활성화 함수가 존재합니다.

|
| [Activation Functions : 출처 https://medium.com, Shruti Jadon] |
3. Keras 모델 컴파일
이제 모델이 정의되었으므로 컴파일이 가능합니다.
컴파일을 진행할때, 학습 (Training)에 필요한 몇가지 추가 속성을 지정해야
하는데 학습을 시킨다는 것은 입력 데이터 세트를 출력에 맵핑하기 위해
최적의 데이터 가중치 집합을 찾는것을 의미합니다.
3 단계 코드
# 3.Compile keras model model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
compile() 함수에 사용된 전달인자인 손실함수 (Loss Function)와 최적화
(Optimizer) 알고리즘, 평가 척도는 다음과 같습니다.
-
loss : 가중치 집합을 평가할 손실함수, 당뇨병여부의 이진 분류이며 Keras에서 "binary_crossentropy"로 정의.
-
optimizer : 최적의 가중치를 찾기위해 적용되는 알고리즘으로, 효율적인 확율적 경사하강법인 "adam"을 사용.
-
metrics : 당뇨병을 분류하는 문제이므로 평가의 척도를 "accuracy" 로 설정.
더 다양한 손실함수, 옵티마이저는
원글에서 링크로 제공되고 있으므로 참조 바랍니다.
4. Keras 모델 학습
앞선 과정에서 우리는 모델을 정의하고 컴파일을 완료하였습니다.
이제는 학습을 진행할 차례입니다.
Keras 모델 클래스의 fit() 함수를 호출해 모델을 학습시킬 수 있습니다.
4 단계 코드
# 4.Fit keras model model.summary() model.fit(x, y, epochs=150, batch_size=10, callbacks=[tb_callback])
fit() 함수의 전달인자는 의미는 다음과 같습니다.
x : 입력 데이터 세트 (8가지 의료 진단 수치)
y : 출력 데이터 세트 (당뇨병 여부)
-
epochs : 전체 트레이닝 데이터세트의 모든 행이 인공신경망을 통과한 횟수, 즉 학습 반복횟수
-
batch_size : 전체 트레이닝 데이터 세트를 소그룹으로 나눌 수, 즉 10명의 당뇨병 데이터로 잘라서 학습을 진행.
부연 설명하자면 만약 600명의 피마 인디언 당뇨병 데이터가 있다면, 이 600명분 데이터 전체를 몇회 학습하는지가 epoch 이고, batch_size는 10명씩 잘라서 진행 (행의 갯수) 하겠다는 표현입니다.
즉 batch_size가 10 이므로 60번을 진행하면 epoch가 1회 완료되며, 전체 행을 통째로 신경망에 넣으면 메모리의 사용이 급증하게 되며 학습이 지연될 수도 있습니다.
TensorFlow는 CPU 뿐 아니라 GPU 학습도 지원하므로, 성능 좋은
그래픽카드를 쓴다면 학습 시간을 단축할 수 있습니다. 다만 NVIDIA사의 CUDA
다운로드 속도 좀 어떻게 해줬으면 좋겠습니다. 또한 비트코인 채굴로 그래픽가드
가격이 너무 비싸서 참 안타까울 뿐입니다.
5. Keras 모델 평가
이제 학습을 마친 모델을 평가해 보겠습니다.
5 단계 코드
# 5.Evaluate keras model
_, accuracy = model.evaluate(x, y)
accuracy *= 100
print(f'Accuracy: {accuracy:#.02f}%')
모델의 evaluate() 함수에 학습에 사용된 것과 동일한 훈련데이터 세트를 전달합니다.
evaluate() 함수는 아래 두개의 리턴값을 가집니다.
-
loss value : 손실값, _로 표현되어 있으며, 받아서 쓰지 않겠다는 의미. (무시, 정확도만 사용)
accuary : 정확도
정확도는 매 학습시 마다 편차를 보이지만 저는 대략 74~77% 정도 입니다.
6. 전체 과정
전체 코드는 아래와 같습니다.
# 0.Prepare for tensorBoard visualization
import os
import tensorflow as tf
from datetime import datetime
_date = datetime.now().strftime('%Y%m%d-%H%M%S')
_logdir = f'Logs/{_date}'
tb_callback = tf.keras.callbacks.TensorBoard(log_dir=_logdir)
from numpy import loadtxt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 1.Load data from csv
dataset = loadtxt('pima-indians-diabetes.data.csv', delimiter=',')
x = dataset[:, 0:8]
y = dataset[:, 8]
# 2.Define keras model
model = Sequential()
model.add(Dense(units=12, input_dim=8, activation='relu'))
model.add(Dense(units=8, activation='relu'))
model.add(Dense(units=1, activation='sigmoid'))
# 3.Compile keras model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 4.Fit keras model
model.summary()
model.fit(x, y, epochs=150, batch_size=10, callbacks=[tb_callback])
# 5.Evaluate keras model
_, accuracy = model.evaluate(x, y)
accuracy *= 100
print(f'Accuracy: {accuracy:#.02f}%')
# 7.Make predictions
#before tf ver 2.5
#predictions = model.predict_classes(x)
#after tf ver 2.6
predictions = model.predict(x)
for i in range(5):
print('%s => %d (expected %d)' % (x[i].tolist(), predictions[i], y[i]))
print('Log Dir:', _logdir)
7. 예측
가장 많이 받는 질문은 아래와 같습니다.
"모델을 학습 시킨 후, 이 학습모델을 사용하여 새 데이터를 예측하려면 어떻게
해야 합니까?"
좋은 질문입니다.
위 모델을 이용해 학습된 데이터세트에 대한 예측(Predict)을 생성하는데 사용할 수 있으며, 기존 데이터를 활용해 새 데이터인 것처럼 적용해 볼 수도 있습니다.
예측을 한다는 것은 모델의 predict() 함수를 이용해 간단히 가능합니다. 우리는 출력레이어에서 Sigmoid 함수를 활성화 함수로 사용하므로, 예측은 0~1사이의 확률값이 되고 이를 반올림해 이진 분류 (당뇨병 여부) 예측이 가능합니다.
예를 들면 아래와 같습니다.
... # make probability predictions with the model predictions = model.predict(X) # round predictions rounded = [round(x[0]) for x in predictions]
위 예제에서 rounded 지능형 리스트에는 [1,0,1,1,...] 형태의 당뇨병 여부가 예측되어 들어가게 됩니다.
(Sigmoid 함수의 결과값인 0~1 사이값을 반올림한 값)
참조로, 지능형 리스트라는 이름은 "Fluent Python"책 저자 루시아누
하말류가 언급하고 있으며, 일반적으로 리스트 컴프리헨션 (List
Comprehension)으로 부르기도 합니다.
또는 아래의 predict_classes() 함수를 호출해 바로 분류된 결과를 볼 수도
있습니다.
... predictions = model.predict_classes(x)
예측 결과는 아래와 같습니다.

|
| [예측 결과] |
대부분 행이 올바른 예측 결과를 가지지만, 샘플의 5번째 결과는 모델의 예측값은 당뇨병이 아님에도 실제 데이터는 당뇨병으로 진단 되었습니다.
앞서 수행한 정확도가 74~77%임을 기억한다면, 이 정도 수준으로 예측될 것임을 예상할 수 있습니다.
이상으로 모든 설명을 마칩니다.
감사합니다.
댓글
댓글 쓰기